Christopher D. HsuI am a PhD student in the Electrical and Systems Engineering department and the GRASP Robotics Laboratory at the University of Pennsylvania, where I work on Spatial AI for Robotics. My PhD advisor is Pratik Chaudhari, Assistant Professor at Penn in ESE with a secondary appointment in CIS. Currently, I am also a Civilian Research Engineer at DEVCOM Army Research Laboratory where our mission is to operationalize science for tranformational overmatch. As a DoD SMART Scholar, I received a MSE in Robotics from the University of Pennsylvania, where I was advised by George J. Pappas and Pratik Chaudhari. I have a BS in Mechanical Engineering from Villanova University, where I worked with C. Nataraj in the Villanova Center for Analytics of Dynamic Systems (VCADS). GitHub / Google Scholar / LinkedIn chsu8 at seas dot upenn dot edu |

|
ResearchI am interested in Spatial AI, simulation, multi-robot systems, reinforcement learning, planning, controls, and robotics. I am also the head of the GRASP SFI Seminar Series committee where we host weekly in-person seminars. See the GRASP Youtube Page for past recordings. |
|
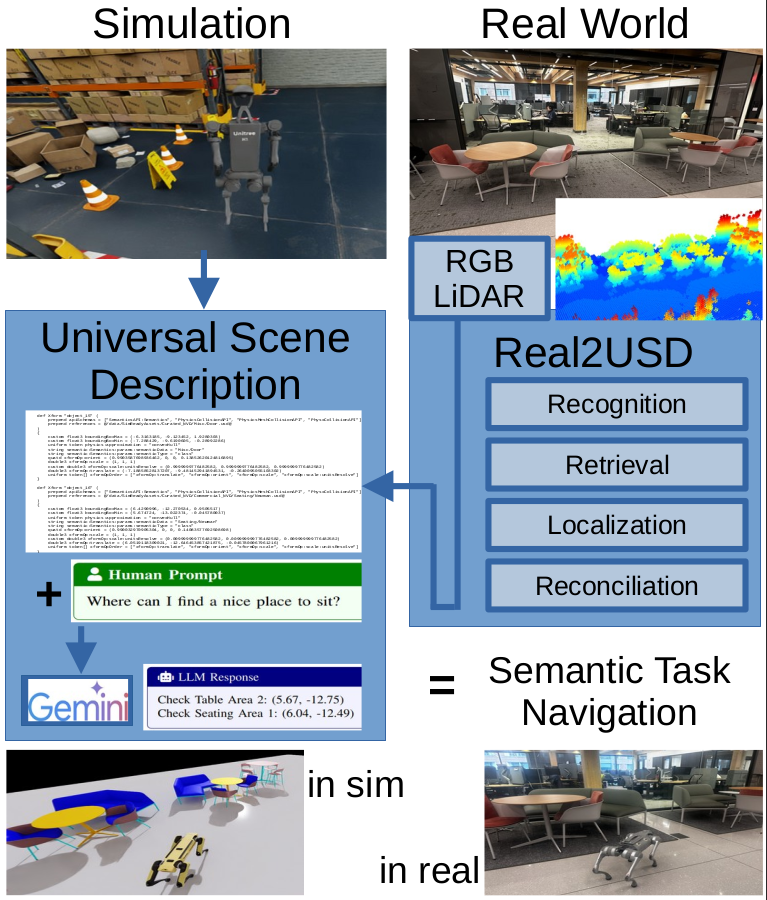
Real2USD: Scene Representations with Universal Scene Description LanguageChristopher D. Hsu and Pratik Chaudhari In Submission to ICRA 2026, 2025 paper / code / Large Language Models (LLMs) can help robots reason about abstract task specifications. This requires augmenting classical representations of the environment used by robots with natural language-based priors. There are a number of existing approaches to doing so, but they are tailored to specific tasks, e.g., visual-language models for navigation, language-guided neural radiance fields for mapping, etc. This paper argues that the Universal Scene Description (USD) language is an effective and general representation of geometric, photometric and semantic information in the environment for LLM-based robotics tasks. Our argument is simple: a USD is an XML-based scene graph, readable by LLMs and humans alike, and rich enough to support essentially any task—Pixar developed this language to store assets, scenes and even movies. We demonstrate a ``Real to USD’’ system using a Unitree Go2 quadruped robot carrying LiDAR and a RGB camera that (i) builds an explicit USD representation of indoor environments with diverse objects and challenging settings with lots of glass, and (ii) parses the USD using Google’s Gemini to demonstrate scene understanding, complex inferences, and planning. We also study different aspects of this system in simulated warehouse and hospital settings using Nvidia’s Issac Sim. |
|
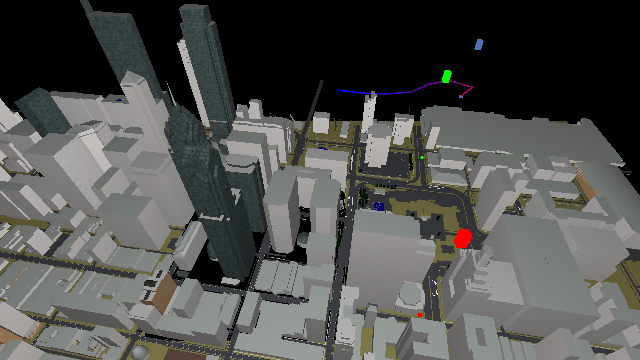
Active Scout: Multi-Target Tracking using Neural Radiance Fields in Dense Urban EnvironmentsChristopher D. Hsu and Pratik Chaudhari IEEE/RSJ International Conference of Intelligent Robotics and Systems (IROS), 2024 paper / code / We study pursuit-evasion games in highly occluded urban environments, e.g. tall buildings in a city, where a scout (quadrotor) tracks multiple dynamic targets on the ground. We show that we can build a neural radiance field (NeRF) representation of the city – online – using RGB and depth images from different vantage points. This representation is used to calculate the information gain to both explore unknown parts of the city and track the targets – thereby giving a completely first-principles approach to actively tracking dynamic targets. We demonstrate, using a custom-built simulator using Open Street Maps data of Philadelphia and New York City, that we can explore and locate 20 stationary targets within 300 steps. This is slower than a greedy baseline which which does not use active perception. But for dynamic targets that actively hide behind occlusions, we show that our approach maintains, at worst, a tracking error of 200m; the greedy baseline can have a tracking error as large as 600m. We observe a number of interesting properties in the scout’s policies, e.g., it switches its attention to track a different target periodically, as the quality of the NeRF representation improves over time, the scout also becomes better in terms of target tracking. |

|
Active Perception using Neural Radiance FieldsSiming He, Christopher D. Hsu, Dexter Ong, Yifei Simon Shao, and Pratik Chaudhari American Controls Conference (ACC), 2024 paper / code / We study active perception from first principles to argue that an autonomous agent performing active perception should maximize the mutual information that past observations posses about future ones. Doing so requires (a) a representation of the scene that summarizes past observations and the ability to update this representation to incorporate new observations (state estimation and mapping), (b) the ability to synthesize new observations of the scene (a generative model), and (c) the ability to select control trajectories that maximize predictive information (planning). This motivates a neural radiance field (NeRF)-like representation which captures photometric, geometric and semantic properties of the scene grounded. This representation is well-suited to synthesizing new observations from different viewpoints. And thereby, a sampling-based planner can be used to calculate the predictive information from synthetic observations along dynamically-feasible trajectories. We use active perception for exploring cluttered indoor environments and employ a notion of semantic uncertainty to check for the successful completion of an exploration task. We demonstrate these ideas via simulation in realistic 3D indoor environments. |
|
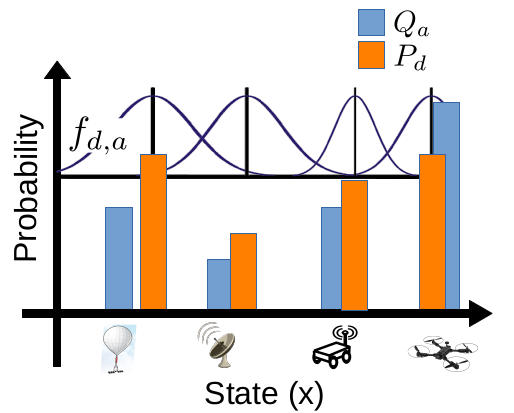
A Model for Perimeter Defense Problems with Heterogeneous TeamsChristopher D. Hsu, Mulugeta A. Haile, and Pratik Chaudhari American Controls Conference (ACC), 2024 paper / code / We introduce a model for multi-agent interaction problems to understand how a heterogeneous team of agents should organize its resources to tackle a heterogeneous team of attackers. This model is inspired by how the human immune system tackles a diverse set of pathogens. The key property of this model is “cross-reactivity” which enables a particular defender type to respond strongly to some attackers but weakly to a few different types of attackers. Due to this, the optimal defender distribution that minimizes the harm incurred by attackers is supported on a discrete set. This allows the defender team to allocate resources to a few types and yet tackle a large number of attacker types. We study this model in different settings to characterize a set of guiding principles for control problems with heterogeneous teams of agents, e.g., sensitivity of the harm to sub-optimal defender distributions, teams consisting of a small number of attackers and defenders, estimating and tackling an evolving attacker distribution, and competition between defenders that gives near-optimal behavior using decentralized computation of the control. We also compare this model with reinforcement-learned policies for the defender team. |
|
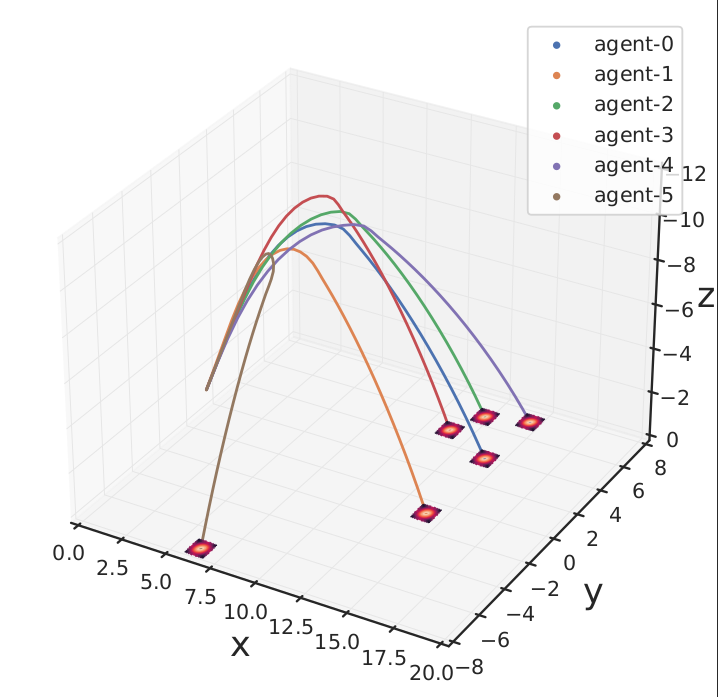
Control algorithms for guidance of autonomous flying agents using reinforcement learningChristopher D. Hsu, Franklin J. Shedleski, and Bethany Allik SPIE Defense and Commerical Sensing (SPIE), 2022 paper / In this paper, we explore the advantages and disadvantages of the traditional guidance law, proportional navigation (ProNav), in comparison to a reinforcement learning algorithm called proximal policy optimization (PPO) for the control of an autonomous agent flying to a target. Through experiments with perfect state estimation, we find that the two strategies under control constraints have their own unique benefits and tradeoffs in terms of accuracy and the resulting bounds on the reachable set of acquiring targets. Interestingly, we discover that it is the combination of the two strategies that results in the best overall performance. Lastly, we show how this policy can be extended to guide multiple agents. |
|
|
Scalable Reinforcement Learning Policies for Multi-Agent ControlChristopher D. Hsu, Heejin Jeong, George J. Pappas, and Pratik Chaudhari IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021 paper / code / We develop a Multi-Agent Reinforcement Learning (MARL) method to learn scalable control policies for target tracking. Our method can handle an arbitrary number of pursuers and targets; we show results for tasks consisting up to 1000 pursuers tracking 1000 targets. We use a decentralized, partially-observable Markov Decision Process framework to model pursuers as agents receiving partial observations (range and bearing) about targets which move using fixed, unknown policies. An attention mechanism is used to parameterize the value function of the agents; this mechanism allows us to handle an arbitrary number of targets. Entropy-regularized off-policy RL methods are used to train a stochastic policy, and we discuss how it enables a hedging behavior between pursuers that leads to a weak form of cooperation in spite of completely decentralized control execution. We further develop a masking heuristic that allows training on smaller problems with few pursuers-targets and execution on much larger problems. Thorough simulation experiments, ablation studies, and comparisons to state of the art algorithms are performed to study the scalability of the approach and robustness of performance to varying numbers of agents and targets. |
|
Design and source code from Leonid Keselman's website |